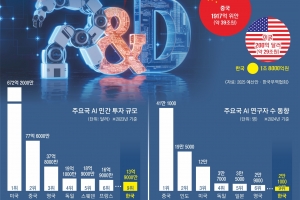
새 정부가 ‘소버린 인공지능(AI)’에 집중하자 그간 외부 빅테크와의 협업이나 인수 등에 관심을 기울였던 국내 통신사들이 자체 모델을 내세우고 나섰다. 특히 KT는 자사의 대규모 언어모델(LLM) 모델 ‘믿:음 2.0’을 오픈소스로 공개하기로 한 것은 물론, 정부가 추진하는 ‘독자 AI 파운데이션 모델 프로젝트’에 참여하겠단 의사를 확고히 했다.
이미지 확대
KT, 한국적 AI ‘믿:음 2.0’ 오픈소스 공개 KT가 ‘한국적 AI’의 철학을 담아 자체 개발한 언어모델(LLM) ‘믿:음 2.0’의 오픈소스를 AI 개발자 플랫폼 허깅페이스를 통해 공개할 예정이라고 3일 밝혔다. KT 기술혁신부문 연구원들이 서초구 KT 우면연구센터에서 믿:음 2.0을 테스트하고 있다. KT 제공
3일 KT는 자체 개발한 LLM인 믿:음 2.0의 오픈소스를 AI 개발자 플랫폼 허깅페이스를 통해 공개할 예정이라고 밝혔다. 믿:음은 KT가 자체 개발한 한국적 독자 AI 모델로, 한국의 사회적 맥락 같은 무형 요소와 한국어 고유의 언어적·문화적 특성을 학습시켜, 한국 상황에 잘 맞게 개량된 AI다. 이번에 오픈소스로 공개됨에 따라 기업과 개인, 공공 누구나 믿:음 2.0을 상업적으로 활용할 수 있게 됐다.
KT는 2023년 10월 믿:음 1.0을 처음 공개했는데, 지난해 9월 마이크로소프트(MS)와 5년간 조 단위의 AI 협력 계약을 체결하자 일각에선 KT가 자체 파운데이션 모델 개발에선 손을 뗀 게 아니냐는 관측이 나오기도 했다. 양사가 협력해 ‘한국적 AI 모델’을 내놓겠다고 밝혔기 때문이다.
이날 브리핑에 앞서 신동훈 KT 생성형 AI 랩장(CAIO) 상무는 이러한 세간의 인식의 의식한 듯 “‘KT가 믿:음 모델의 개발을 중단한 것이 아니냐’하는 의문을 갖고 바라보는 분들이 많은 것 같다”면서 “지난해 7월 합류한 이후 지속적으로 믿음을 개발을 해왔다. KT는 한 번도 이런 자체 기술을 기반으로 한 믿음 모델의 개발을 멈춘 적이 없다”고 강조했다.
MS와 협력하면서 굳이 자체 모델을 개발하는 이유에 대해 신 상무는 “기간 통신 사업자로서 생성형 AI 원천 기술을 반드시 확보해야 한다는 믿음으로 믿:음 모델을 고도화했다”면서 “MS와의 협력을 통해서는 챗GPT 같은 모델을 한국 시장에 맞게 튜닝해서 제공할 예정”이라고 설명했다. 그러면서 “정부가 추진하는 ‘독자 AI 파운데이션 모델 프로젝트’에 참여하려고 준비 중”이라고 말했다.
이번에 오픈소스로 공개될 믿:음 2.0은 115억 파라미터(매개변수) 규모의 ‘믿:음 2.0 베이스’와 23억 파라미터 규모 ‘믿:음 2.0 미니’ 2종으로 출시되며 한국어와 영어를 지원한다. 베이스 모델은 범용 서비스에 적합한 모델로 한국 특화 지식과 문서 기반 질의응답에서 강력한 성능을 보였다는 설명이다. 향후 고성능 ‘프로’ 모델도 출시될 예정이며, 이후 추론모델이나 멀티모달 모델들도 순차적으로 공개될 예정이다.
같은 날 SK텔레콤 역시 한국어 특화 LLM A.X(에이닷 엑스) 4.0을 오픈소스로 공개했다. 이와 관련해 KT는 “에이닷 표준 모델은 720억개(72B), 경량 모델은 70억개(7B)의 매개변수를 가지고 있어 (믿:음에 비해) 더 큰 모델이라 직접 비교하는 것은 의미가 없다”면서도 “내부적으로 프리뷰 단계에 있는 (믿:음) 프로 모델이 그 정도를 상응하는 성능을 확보하고 있다”고 설명했다.
이어 “데이터 학습 측면에서 KT는 초기 단계부터 모두 저희가 학습한 모델이라며, SK텔레콤은 외부 모델을 기반으로 중간 단계부터 추가적인 학습을 했다는 점이 다르다”고 덧붙였다.
한편 KT는 국산 AI 생태계 구축을 위해 개발 과정에서 리벨리온 등 국내 신경망 처리장치(NPU) 기업과 협업했다.
민나리 기자
Copyright ⓒ 서울신문 All rights reserved. 무단 전재-재배포, AI 학습 및 활용 금지